
How to plan and implement a customer data tracking strategy for your Micro-SaaS
From start to finish, learn how I'm tracking customer key events and behaviour across the portfolio

You can’t improve what you can’t measure.
You’ve heard it many times before, and you might even be intentional about what you want to track.
But I’ve noticed that most technical marketers — and even developers — don’t have the ability to plan a strategy to track that data, never mind implement it.
Let’s go through that process together from A to Z, so you can both understand and be exposed to what a starter iteration might look like for your own product or one you’ll work on in the future.
For what it’s worth, I’ve made great money as a consultant implementing customer data platforms for clients because the work is technical but also highly valuable vis-a-vis the kind of activities it unlocks.
There are a variety of tools for doing this.
My historical favorite is Segment by I’ve recently picked up Rudderstack which is younger, less polished but with an open source offering.
I’m going to use Rudderstack for Reconcilely because I’m wary of new costs, and have in the past been burned by vendor lock-in when my Segment events (and MTUs) started to grow out of proportion.
In one project, the problem became so severe (as a result of producing a ton of data from customers using the product) that we had to stop sending some of the more volume-heavy events to our analytics tools, which coincidentally reduced their utility from containing incomplete data.
Instead of running into that inevitable compromise, I’ll try the open source alternative. If push comes to shove, migrating to Segment is a matter of commenting out 2 lines of code.
First, let’s go through the process to deliver this task:
Define event dictionary for tracking
Define the traits to be tracked for individual users
Create a Rudderstack account or host the FOSS version yourself
Create Node.js & JavaScript sources to send from
Implement identify and event tracking for Node.js source
Sanitize + verify data accuracy and integrity
In the end, what we want is the ability to understand how customers are using the product, and send enough data to our analytics tools so those tools can tell us which combination of events and traits produce the highest likelihood of customer success.
Specifically, the goals for the analytics strategy are to:
Get visibility on the top of the funnel through to conversion
Discover and keep track of customer retention KPIs
Quantify the impact of changes brought upon the product/funnel
Let’s get to it!
1. Define event dictionary for tracking
Garbage in, garbage out — a hard lesson to learn by anyone not careful and intentional about what events are sent to your tooling, from the way you’ve named them to the exact locations in your code where the events are sent (for debugging).
You don’t want to send events for everything happening within your product. Only for the events within your funnel that have direct influence over that funnel. Those are the key performance indicators of that funnel, which is why you ought to track them.
Vanity metrics pollute your data stack and make it more difficult to make use of machine learning because the models will take into account data that won’t have any impact on your optimization efforts.
The best way to define the events is to start from the technical foundation of the product, which is the database tables.
Your database describes the core models of your application and the things that can be interacted with which interact with other things in your app.
The vast majority of applications out there have a User model. For Shopify apps, that is a shop.
Whenever a Shopify merchant installs our app, we create a new entry in the shopify database, which is filled with merchants. Each row in that database contains a variety of columns/properties that are attached to that merchant, such as their store URL, whether they are active, the last time we sent a payout for them, and so on.
Each model in your application likely plays a large role within it, so take the time to clearly define which of those are at play and then consider what type of actions are available to that model.
For example, most RESTful apps will offer models the ability to be created, read, updated and eventually deleted. A user can be created/read/updated/deleted. A payout can be created/read/updated/deleted. And so on.

Once you understand what is naturally part of the user experience, you can keep note of which models (and actions) the user interacts with during their user of the product, which should become things you track so you can chart out the user’s experience and quantify it.
2. Define the traits to be tracked for individual users
While it’s important to keep track of events that happen within the product, that only represents one dimension where we are concerned with tracking user behaviour and experience.
A second and equally important dimension is the traits that describe the user at any given point in time.
Generally speaking, we want to enable marketing automation software by sending it data about users that can be used as the personalization elements of that marketing automation.
Where the events describe what is happening, the trait data explains for who and how that event has affected the general composition of the customer.
For example, I want to keep track of whether a user has a valid Xero connection, otherwise they won’t be getting any value from the product.
I can only trigger automation to remedy this if I know which users have an invalid Xero connection (where the Shopify model’s xero_connection_ok column is false). And I can know that by identifying the user in my app and passing to the CDP any and all traits that describe the merchant in time.
For now this is how I’ve described the traits for merchants using Reconcilely:
const userTraits = {
name: shopify.shop_info.shop_owner,
username: shopify.shop,
active: shopify.active,
email: shopify.email,
company: {
name: shopify.shop_info.name,
shop: shopify.shop,
plan: shopify.plan_name,
},
phone: shopify.shop_info.phone,
currentMonthlyTotal: shopify.current_monthly_total,
canBackdate: shopify.can_backdate,
onboardingCompleted: shopify.onboarding_completed
lastPayoutFetch: shopify.last_payout_fetch,
currency: shopify.currency,
xero_connection_ok: shopify.xero_connection_ok,
}Effectively, I’m simply passing the data from my database columns directly, since I’m already tracking them internally and just want to make them available.
Now, if I pipe data from Rudderstack to, say, Intercom, and a live chat gets created with a customer, that customer’s profile will contain all of these traits, giving me and my support team all of the context required to understand how the merchants stands.
These traits get passed to Rudderstack anytime I want to identify the user, and I want to identify a user anytime something changes in the app (or if they log in, so calculating daily active users can be possible).
3. Create a Rudderstack account or host the FOSS version
At this point, you can go ahead and create yourself an account on Segment or Rudderstack. If you’ve got some devops skills, you can also host it yourself with Kubernetes.
I doubt I’ll need more than the 500,000 events per month that are offered within Rudderstack’s free account. If I ever do go over, I’ll opt for the open source implementation.
Since I run on a Node.js stack with a React front-end, I’m going to use the Node.js and JavaScript SDKs to rapidly integrate Rudderstack’s library into the product and start sending data.

4. Create sources for backend/frontend tracking
Historically, most of the logic will be stored in your backend (hopefully) and your server operations are typically where it’ll make the most sense to drop in identify and track calls as those are the lines of code responsible for mutating data, which is the type of stuff you want to be tracking.
When you create a source, Rudderstack (and Segment) will give you a special write key specific to that source.
When you send events using that key, Rudderstack will understand it’s for this source, while also making sure only you (or anyone with the key) can send events.
5. Implement identify and event tracking for Node.js source
Time to dig in.
Instead of rewriting event calling each time we need it, we’ll avoid that by creating and exporting a few reusable functions that can standardize the process of sending data to Rudderstack for us.
For starters, start by grabbing the SDK with npm
npm install --save @rudderstack/rudder-sdk-node Then, in your lib folder, create a new file called rudderstack.js or similar. To use the library, you’ll need to require and instantiate it at the top of your file:
const Analytics = require("@rudderstack/rudder-sdk-node")
const analytics = new Analytics(env.rudderstackWriteKey, `${env.rudderstackDataPlaneUrl}/v1/batch`)Almost there!
Now, the analytics variable contains a few methods that correspond to the type of data you want to send.
For this example, we’ll stick to just identify and track, which are the two most common ones.

First the identify call.
I start off by defining the traits I’m going to be reusing across the different calls in a userTraits variable.
Then, we define a identify() function that takes in a shopify ID or domain in this case. You don’t have to do it this way, but I did that for flexibility since I’m unsure which of the two I’ll have access to down the line.
In the function, I use the ID or domain to find the Shopify merchant in my database and assign it to the shopify variable, which now holds all of the traits that userTraits includes.
Lastly, we store the actual identify call in a try/catch call in case something goes wrong. This is useful at first when trying to figure out what the object you send should look like.
In the case of identify, you need to pass it an object containing at minimum a userId. The traits are optional for the API call, but I think they’re the pretty much a must-have otherwise the user you identify will be missing all of the contextual data you’ll want.
Now, when you export the identify function and import it elsewhere in your stack, you can simply call it by passing in an ID or domain to identify the store.

Tracking events is really similar.
The only difference is that since we’re tracking a specific event, I want to also pass it an eventName describing the event as well as any additional traits that can contextualize the event.
For example, consider the “customer charged” event which I might fire when a subscription payment is captured.
An additional trait in such an event might be the “amount” captured within the scope of the customer charge. These additional properties give meaning to the event, and in the framework of marketing automation, provide critical personalization for your eventual messaging.
Then you just call them as usual:


Technically, this is all it takes to implement. You’ll want to ensure you cover all of your dictionary’s events across your stack so you’re tracking everything you need to.
6. Sanitize + verify data accuracy and integrity
Before sending off the data to different tools and destinations, it’s important to validate it’s accurately being received (as that’s what will be sent to your tools).
You can do this on Rudderstack by accessing Live Events of a given source.

This will give you access to a debug log that shows the events and identify calls received by the source.
I’ll go ahead and save some new mappings on my test Reconcilely account.
What should happen is that as soon as I load the settings page, the customer will be identified. Once the settings are updated, the tracking call will be executed.
First, let’s head to the mappings page to test the identify call:
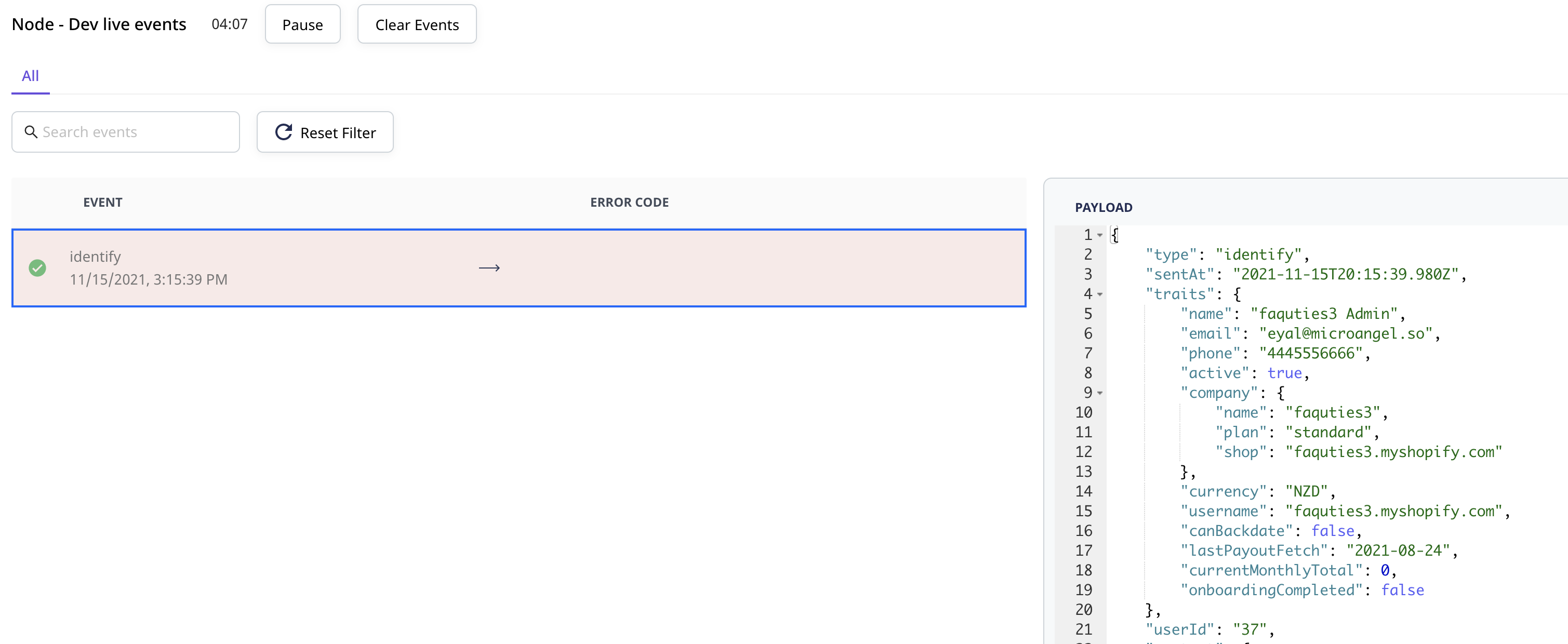
Yay! And now if I save any of my settings…
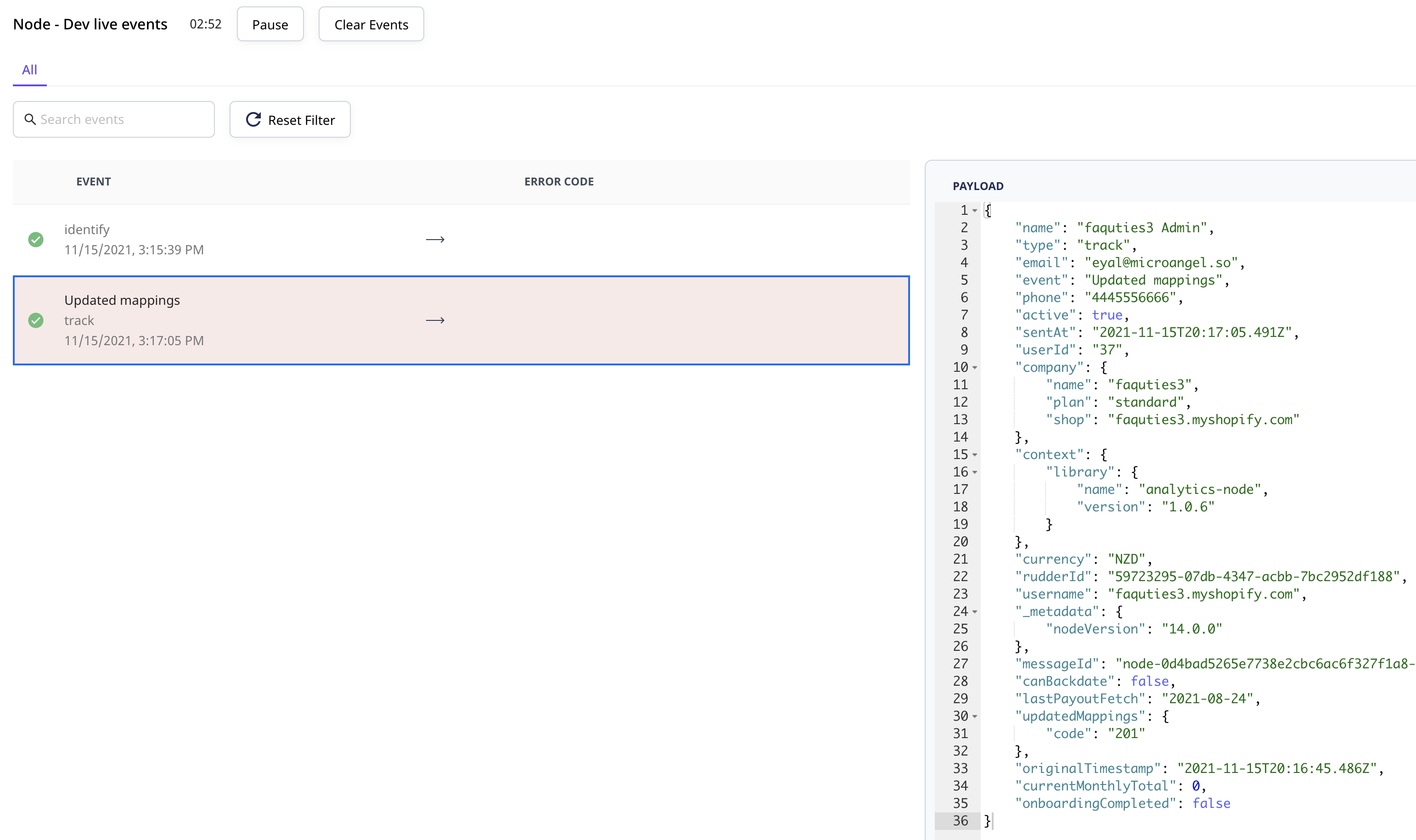
There it is!
These two calls are the foundation of implementing a data tracking strategy. Provided you are really deliberate about what you track, you can now start to pipe these events to a variety of different tools without ever having to reimplement the same information.
The main purpose of a CDP platform like Segment or Rudderstack is that you only need to do the implementation once, and you can then pipe the same standardized data across all of the tools your use, from Facebook pixels and audiences to Google Analytics to Mailchimp to Intercom and so on.
From this point on, you can democratize this data across as many tools as you need by creating Destinations on Rudderstack and defining within them the traits you wish to assign to profiles.
Hopefully this guide shortens your implementation journey next time it’s needed in a project. Don’t hesitate to get in touch if you have any thoughts or questions on the matter. Happy to help.
Till next time!